반응형
데이터 추출
1. loc : 명시적 location
2. iloc : 암묵적 location
.loc : 명시적인 인덱스를 참조하는 인덱싱/슬라이싱
인덱스 값을 알고 있을때 사용한다.
country.loc['china'] #인덱스가 china인 것의 데이터 추출
country.loc['japen':'korea', :'population'] #슬라이싱으로 데이터 추출
.iloc : 파이썬 스타일의 정수 인덱스 인덱싱/슬라이싱 (암묵적인 순서에 따라 출력)
구체적인 컬럼이나 인덱스명 모를때 사용한다.
country.iloc[0] #인덱스
country.iloc[1:3, :2] #슬라이싱
컬럼명 자체를 활용하여 DataFrame에서 데이터 선택도 가능
country
country['gdp'] # Series로 출력 / 컬럼 그 자체
country[['gdp']] # DataFrame으로 출력 / 데이터 프레임
Masking 연산이나 query 함수를 활용하여 조건에 맞는 DataFrame 행 추출 가능
country[country['population']<10000] # masking 연산 활용 => 결과 값 데이터프레임 형태임
country.query("population > 10000") # query함수 활용
Series도 numpy array처럼 연산자 활용 가능
gdp_per_capita = country['gdp']/country['population']
#country DataFrame에 새로운 시리즈 추가
country['gdp per capita'] = gdp_per_capita
데이터 프레임에 새로운 데이터 추가
1. 리스트로 추가
2. 딕셔너리로 추가
df = pd.DaraFrame(columns = ['이름', '나이', '주소']) #열의 이름과 함께 데이터프레임 생성
df.loc[0] = ['길동', '26', '서울'] #리스트로 데이터 추가
df.loc[1] = {'이름' : '철수', '나이': '25', '주소' : '인천'} #딕셔너리로 데이터 추가
df.loc[1, '이름'] = '영희' # 명시적 인덱스 활용하여 데이터 수정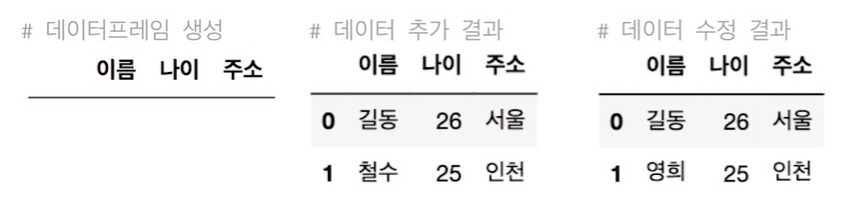
NaN값으로 초기화 한 새로운 컬럼 추가
df['전화번호'] = np.nan #새로운 컬럼 추가 후 초기화
df.loc[0, '전화번호'] = '010000000' #명시적 인덱스를 활용하여 데이터 수정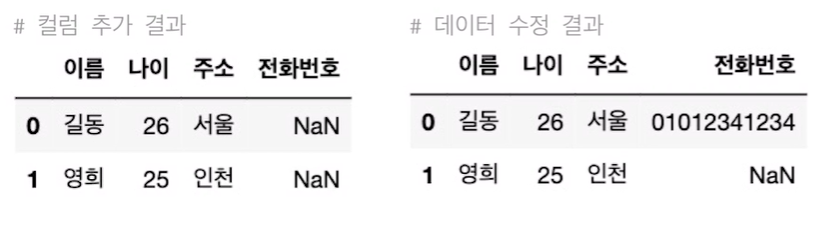
DataFrame에서 컬럼 삭제 후 원본 변경
df.drop('전화변호', axis=1. inplace=True) #컬럼 삭제
#axis = 1 : 열 방향, axis = 0 : 행 방향
#inplace = True : 원본 변경, inplcae = False : 원본변경 X

.
실습
import numpy as np
import pandas as pd
print("Masking & query")
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
print(df, "\n")
# # 데이터 프레임에서 A컬럼값이 0.5보다 작고 B컬럼 값이 0.3보다 큰값들을 구해봅시다.
# # 마스킹 연산을 활용
print(df[(df['A']<0.5) & (df['B']>0.3 )])
# query 함수를 활용
print(df.query("A<0.5" and "B>0.3"))728x90
반응형